Publications
Authors marked with an asterisk contributed equally. See also my Google Scholar profile.

Under review at Conference on Robot Learning (CoRL) 2026 · senior thesis
RA-VLA retrieves a semantically similar demonstration from a large robot dataset, warps it to the current scene with a multimodal language model, and overlays it as guidance for a fine-tuned policy. It improves task success on the RoboLab-120 simulator and real-world tasks with no new demonstrations collected.
Under review at NeurIPS
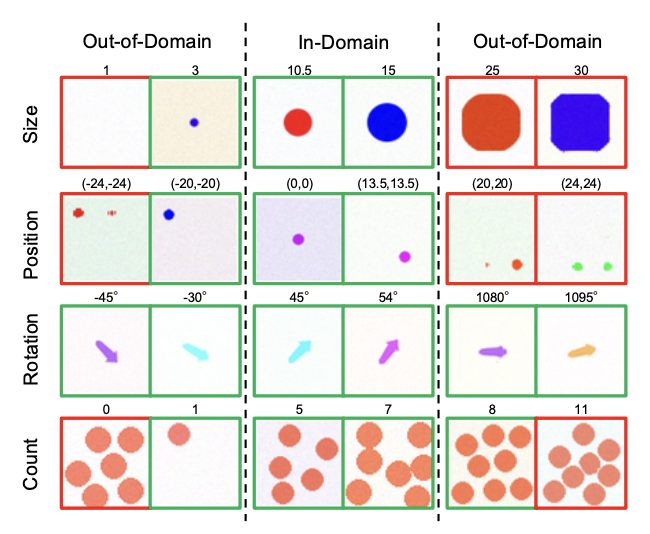
A controlled study trains diffusion models on synthetic data that isolates size, position, and rotation, showing they interpolate well within the training distribution yet fail to extrapolate beyond it.
Under review at COLM · published at the NeurIPS 2025 ER Workshop
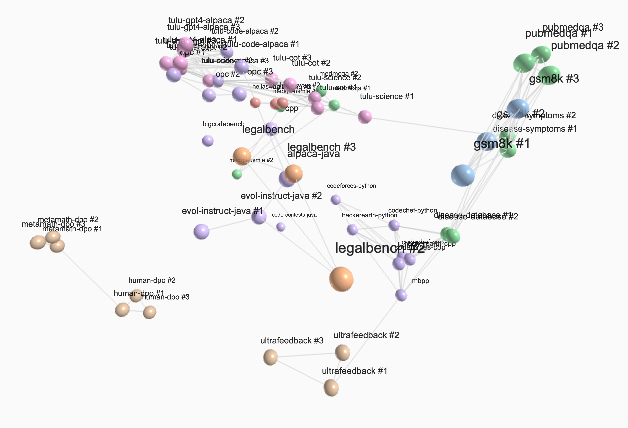
Delta Activations represent a finetuned model by how its internal activations shift from a base model, which clusters models by domain and enables task based retrieval. I led the experiments and released more than 700 finetuned open-source models on Hugging Face.

NeurIPS 2025 · Spotlight, top 3%
ESCA turns video into spatio-temporal scene graphs that give vision language models explicit spatial context, cutting perception errors from 69 percent to 30 percent on EmbodiedBench without retraining the underlying models.


CLAM unifies finetuning, quantization, and pruning as weight based adaptations that chain freely, letting CLAM compositions match uncompressed models while using 86 percent fewer bits.

Foundation model behind ESCA
VINE turns video into probabilistic scene graphs of entities, attributes, and relations. Trained on more than 87,000 videos with neurosymbolic learning, it is promptable and finetunable for many downstream tasks.

bioRxiv, 2021 · ISEF Finalist
Using clustering and dimensionality reduction, this work found genes that differ in Alzheimer's and predicted the disease from peripheral blood gene expression with 98 percent accuracy. Cited more than 8 times.